Spark-TTS
综合介绍
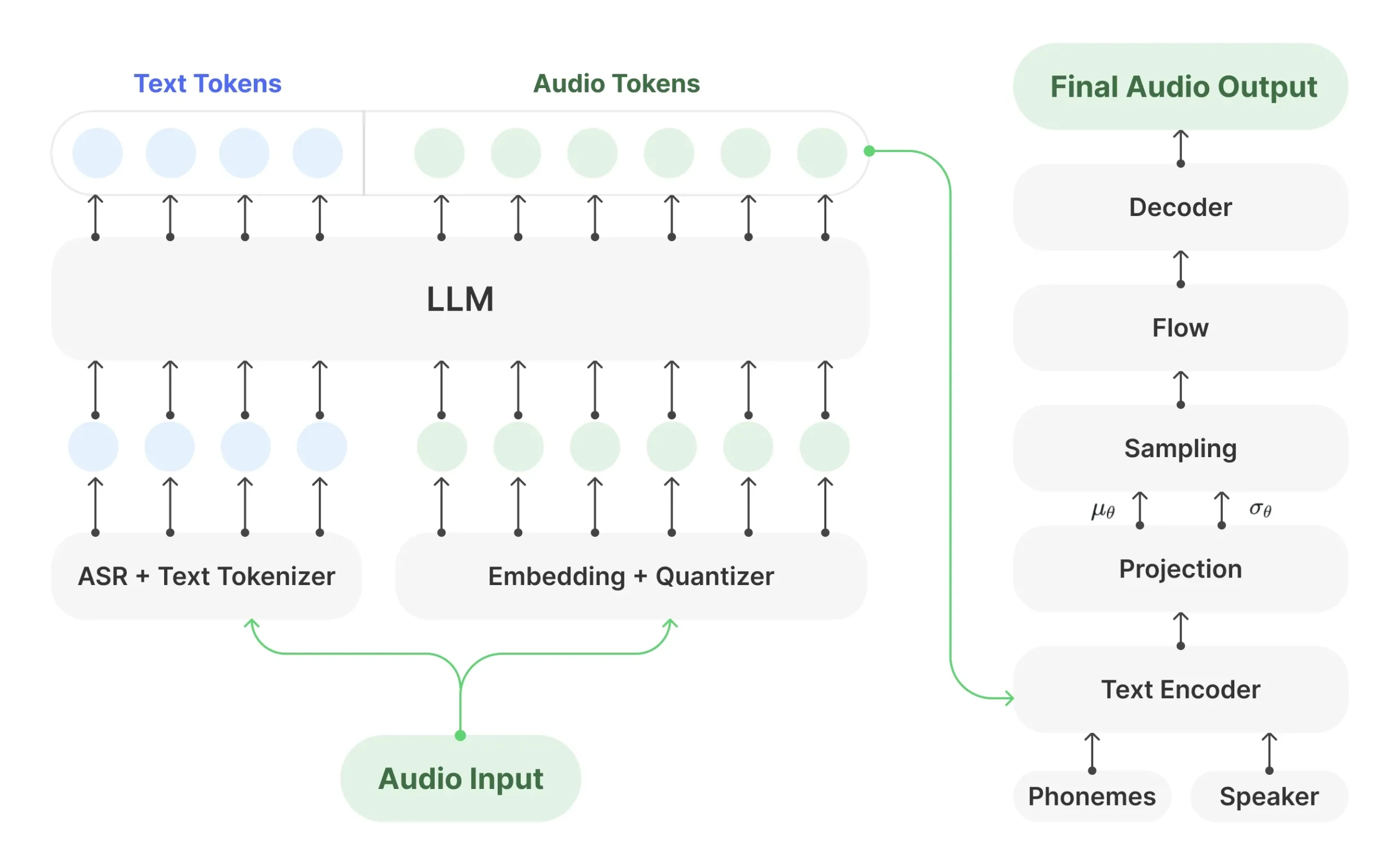
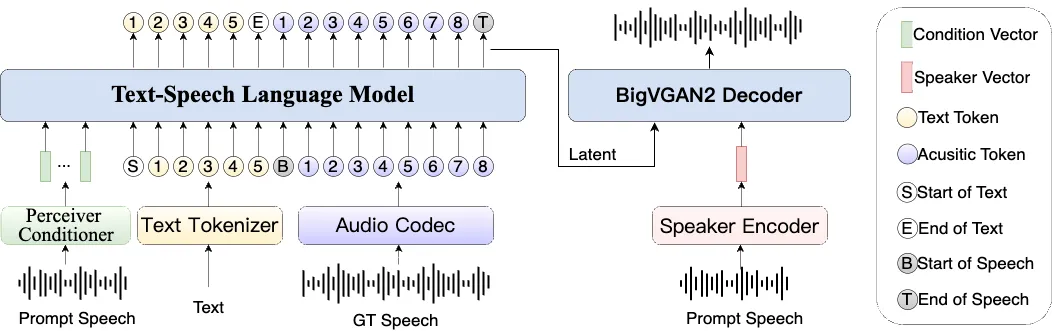
Spark-TTS是一个先进的文本转语音(TTS)系统,它利用大语言模型(LLM)的技术来生成非常自然和准确的人声。这个项目的设计目标是兼具高效率和灵活性,既可以用于学术研究,也能在实际生产环境中使用。它的核心特点是简化了传统TTS模型的复杂结构,完全基于Qwen2.5大模型,不再需要一个独立的声学模型来生成音频特征,而是直接通过大模型预测的编码来重建语音。这种方式不仅提升了效率,也降低了系统的复杂度。此外,Spark-TTS支持高质量的声音克隆,即使模型没有经过特定声音的训练,也能通过“零样本”学习来复制一个人的声音,这个功能对于需要中英文之间切换的场景尤其有用。
功能列表
- 高效一体化架构:整个系统完全基于大语言模型构建,直接从文本生成语音,无需额外的声流匹配等模型,简化了流程并提升了运行效率。
- 高质量声音克隆:支持零样本(zero-shot)声音克隆,只需一小段目标声音的音频片段,即可模仿该声音的音色和风格,并合成新的语音内容。
- 跨语言与双语支持:原生支持中文和英文两种语言,并且可以在不同语言之间进行声音克隆,生成的语音在跨语言场景下依然保持高度的自然感。
- 可控的语音生成:用户可以通过调整性别、音高、语速等参数来创造新的虚拟声音,实现对生成语音的精细化控制。
- 便捷的用户界面:提供命令行(CLI)和网页图形界面(Web UI)两种操作方式,用户可以根据自己的需求选择合适的方式进行交互。
- 生产环境部署方案:支持通过Nvidia Triton推理服务器进行部署,并结合TensorRT-LLM进行优化,确保在生产环境中的高性能和低延迟。
- 多种使用方式:支持直接录音或上传音频文件作为声音克隆的参考。
使用帮助
Spark-TTS提供了多种使用方式,包括命令行和图形化网页界面。以下是详细的安装和使用流程,旨在帮助用户快速上手。
环境安装
在开始使用之前,请确保你的电脑已经安装了Conda环境管理工具。推荐使用Python 3.12版本。
- 克隆代码仓库首先,打开终端(Terminal),使用git命令将项目代码从GitHub克隆到你的本地电脑。
git clone https://github.com/SparkAudio/Spark-TTS.git - 进入项目目录使用
cd命令进入刚刚克隆下来的文件夹。cd Spark-TTS - 创建并激活Conda环境为了隔离项目依赖,我们创建一个独立的conda环境,并将其命名为
sparktts。conda create -n sparktts -y python=3.12 conda activate sparktts - 安装依赖库项目所需的全部依赖库都记录在
requirements.txt文件中。使用pip命令进行安装。pip install -r requirements.txt提示:如果你的网络环境在中国大陆,可以添加镜像源来加速下载:
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
模型下载
在运行程序之前,需要先下载预训练好的模型文件。模型托管在Hugging Face平台,你可以选择以下任意一种方式进行下载。
- 通过Python脚本下载在你的Python环境中运行以下代码,它会自动从Hugging Face下载模型并存放到指定目录。
from huggingface_hub import snapshot_download snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B") - 通过Git命令下载确保你的电脑已经安装了
git-lfs(用于处理大文件)。# 创建存放模型的文件夹 mkdir -p pretrained_models # 确保git-lfs已安装 git lfs install # 克隆模型仓库 git clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B
功能操作流程
1. 命令行操作
对于习惯使用命令行的用户,可以直接调用脚本来生成语音。
- 基本命令格式:
python -m cli.inference \ --text "你想要合成的文本内容放在这里。" \ --prompt_speech_path "path/to/prompt_audio.wav" \ --prompt_text "参考音频里对应的文本内容。" \ --model_dir "pretrained_models/Spark-TTS-0.5B" \ --save_dir "output_audios" \ --device 0 - 参数详解:
--text: 你希望模型为你朗读的文本。--prompt_speech_path: 用于声音克隆的参考音频文件路径(例如.wav格式)。这个音频的音色将被克隆。--prompt_text: 参考音频文件中所说的具体文本内容。提供此文本有助于模型更好地学习音色。--model_dir: 指向你下载好的预训练模型文件夹的路径。--save_dir: 生成的音频文件的保存目录。--device: 指定使用的计算设备,0通常代表第一块GPU,也可以设置为cpu。
- 快速测试:项目
example目录下提供了一个示例脚本,你可以直接运行它来快速验证环境是否配置成功。cd example bash infer.sh
2. 图形化网页界面(Web UI)操作
为了方便不熟悉命令行的用户,项目提供了一个基于Gradio的网页界面,操作更直观。
- 启动Web UI在终端中运行以下命令来启动网页服务。
python webui.py --device 0启动成功后,终端会显示一个本地网址(通常是
http://127.0.0.1:7860),在浏览器中打开此地址即可看到操作界面。 - 界面功能Web UI主要分为两个功能区:“声音克隆”和“声音创造”。
- 声音克隆 (Voice Cloning):
- 输入文本: 在“合成文本”输入框中,填入你希望生成的语音内容。
- 提供参考音频: 你有两种方式提供声音样本。
- 上传文件: 点击上传区域,选择一个本地的音频文件(如
.wav,.mp3)。 - 在线录音: 点击“录制音频”按钮,直接用麦克风录制一段声音。
- 上传文件: 点击上传区域,选择一个本地的音频文件(如
- 输入参考文本: 在“参考文本”框中,输入你刚刚上传或录制的音频中包含的文字。
- 生成语音: 点击“合成”按钮,稍等片刻,生成的音频会出现在右侧的播放器中,你可以直接试听或下载。
- 声音创造 (Voice Creation):这个功能允许你通过调整参数来创造一个全新的虚拟声音,而无需提供参考音频。
- 输入文本: 在“合成文本”框中输入文字。
- 调整参数: 拖动滑块来调整“性别”、“音高”和“语速”等参数。
- 生成语音: 点击“合成”按钮,系统会根据你设定的参数生成一个独特的声音。
- 声音克隆 (Voice Cloning):
应用场景
- 个性化内容创作为视频、播客或有声读物生成具有特定情感和风格的配音。创作者可以克隆自己的声音,实现批量内容制作,或创造一个独特的虚拟主播形象。
- 智能语音助手作为智能设备或应用软件的语音引擎,提供更加自然和人性化的语音交互体验。用户可以根据喜好定制助手的音色。
- 教育与语言学习为语言学习软件生成标准发音的教学内容,或通过克隆不同人的声音来创建多样化的对话场景,帮助学习者适应不同的口音和语速。
- 辅助技术为有语言障碍的用户提供发声辅助,将他们输入的文字转换为流畅的语音输出,帮助他们与外界进行更顺畅的沟通。
QA
- 这个模型支持哪些语言?目前主要支持中文和英文,并能在这两种语言之间进行高质量的跨语言声音克隆。
- 什么是“零样本”声音克隆?“零样本”(Zero-shot)指的是模型在没有经过特定说话人声音训练的情况下,仅凭一小段该说话人的音频样本(通常几秒钟即可),就能成功模仿其音色、韵律和风格来合成新的语音。
- 使用这个模型对硬件有什么要求吗?为了获得较好的性能和生成速度,推荐在配备NVIDIA GPU的设备上运行。同时也支持在CPU或苹果的MPS上运行,但速度会慢一些。详细的依赖环境请参考
requirements.txt文件。 - 我可以使用这个模型进行商业活动吗?该项目遵循Apache-2.0开源协议,但开发者明确声明,禁止将此模型用于任何非法活动,如未授权的声音克隆、欺诈、制作深度伪造内容等。任何商业使用都必须遵守相关法律法规并承担相应的责任。